Whisper.cpp benchmarking results
Introduction
I’m currently working on improved Whisper model configuration in Hello Transcribe, which includes adding “Medium” and “Large” to macOS.
I wrote an app I can run on iOS, iPadOS and macOS to benchmark 5 different scenarios:
- 5 seconds of audio using CPU.
- 30 seconds of audio using CPU.
- 5 seconds of audio using CoreML.
- 30 seconds of audio using CoreML.
- The CoreML optimisation & caching phase.
The CoreML optimisation & caching phase is an internal process which can take a very long time and consume a lot of memory, and has surprisingly different behaviour on iOS and macOS.
The upcoming iOS 17 and macOS 14 also have significant differences.
I have access to 2 iPhones, one iPad and one Mac so have the following devices and OS combinations tp test:
- iPhone 14 Pro with iOS 16
- iPhone 12 Pro with iOS 17 Beta
- iPad Pro 11” with iOS 16
- Macbook Pro M1 Max with either macOS 13 or macOS 14 Beta
Let look at some results.
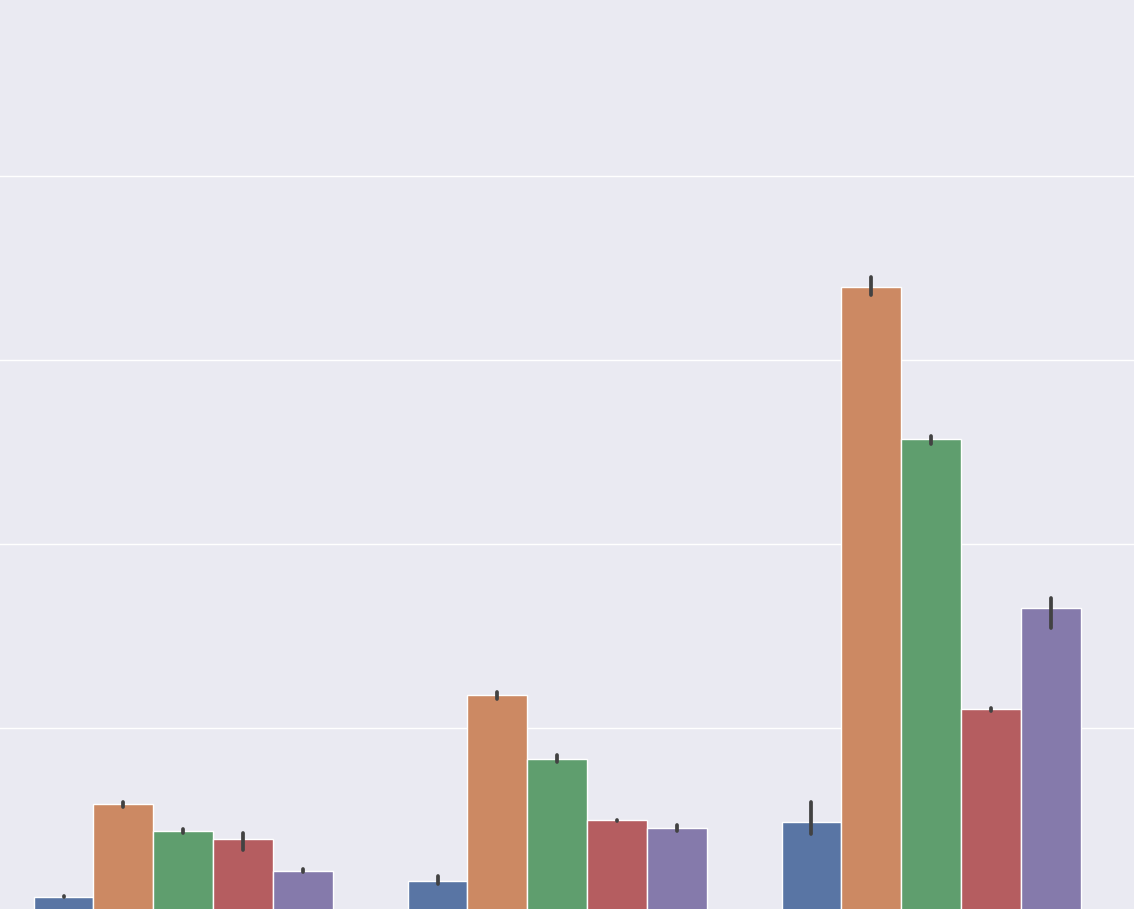
5s audio transcription time
Here are the results for transcribing 5 seconds of audio using the “small” model with CPU and CoreML:
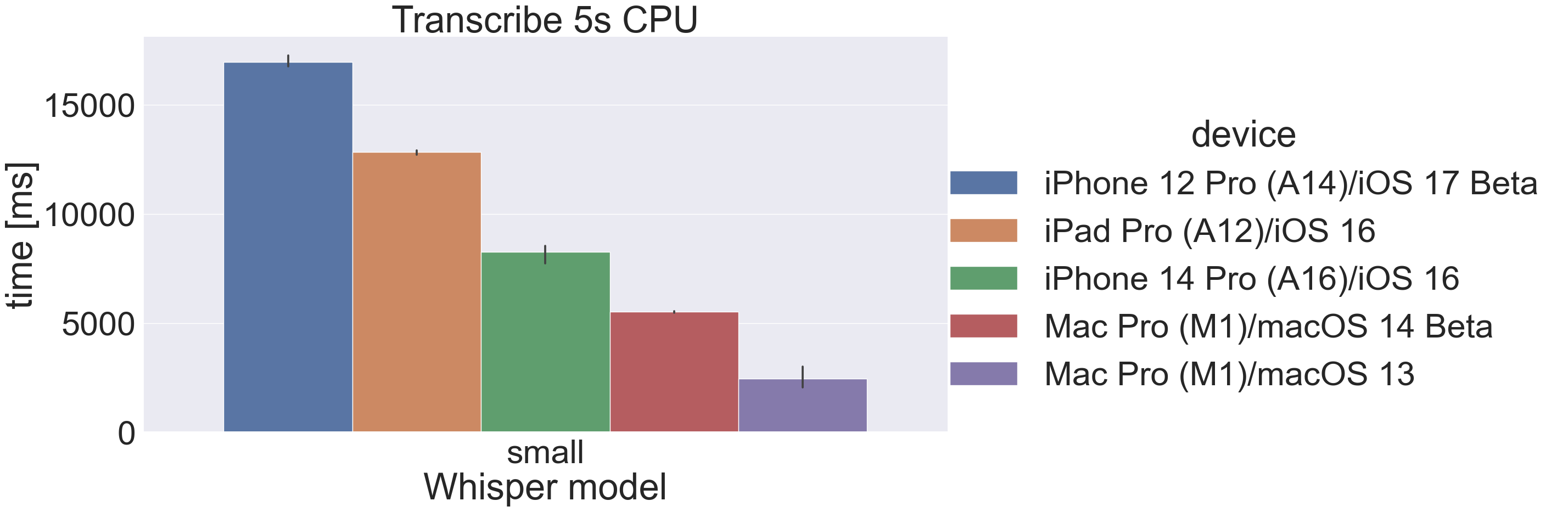
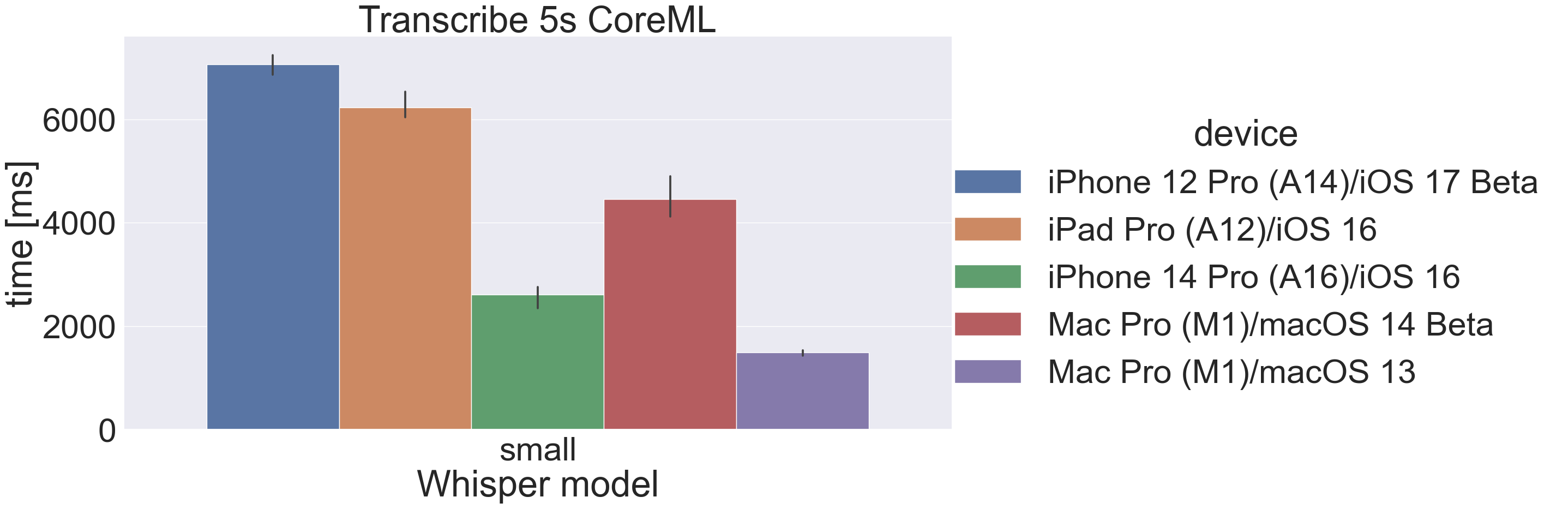
Some observations:
- CoreML inference on mobile devices give a significant performance boost, especially iPhone 14 Pro with has a new (for now) Neural Engine.
- macOS 14 Beta is significantly slower in CPU and CoreML scenarios than macOS 13 on the same hardware. I hope this changes when macOS 14 is released. macOS 14 Beta does fix an issue with caching “small” though (see below).
- The improvement using CoreML on macOS is not as big as on iOS (more on that below).
The benchmarks have a lot of dimensions so I will highlight some more usable benchmarks that compare apples with apples.
CPU vs CoreML on iOS
Nothing surprising here, CoreML offers significant performance improvements on iPhone 14 with a recent ANE (Apple Neural Engine):
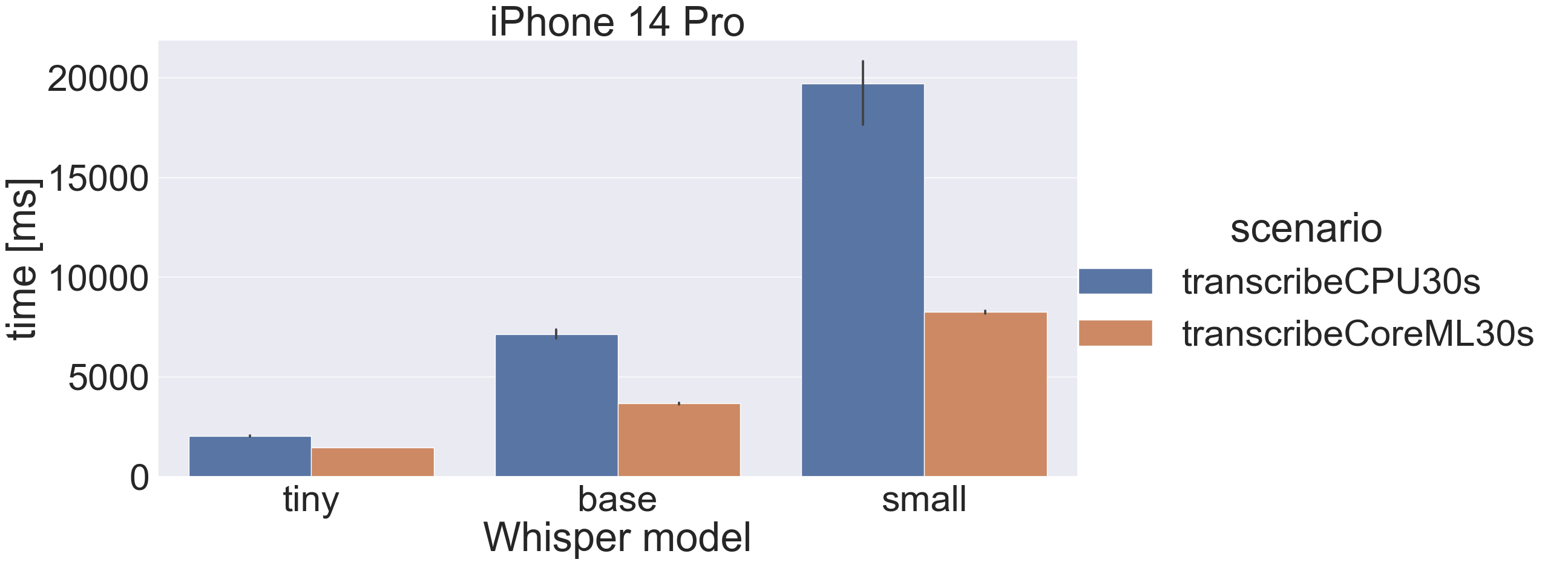
The drawback is CoreML model caching:
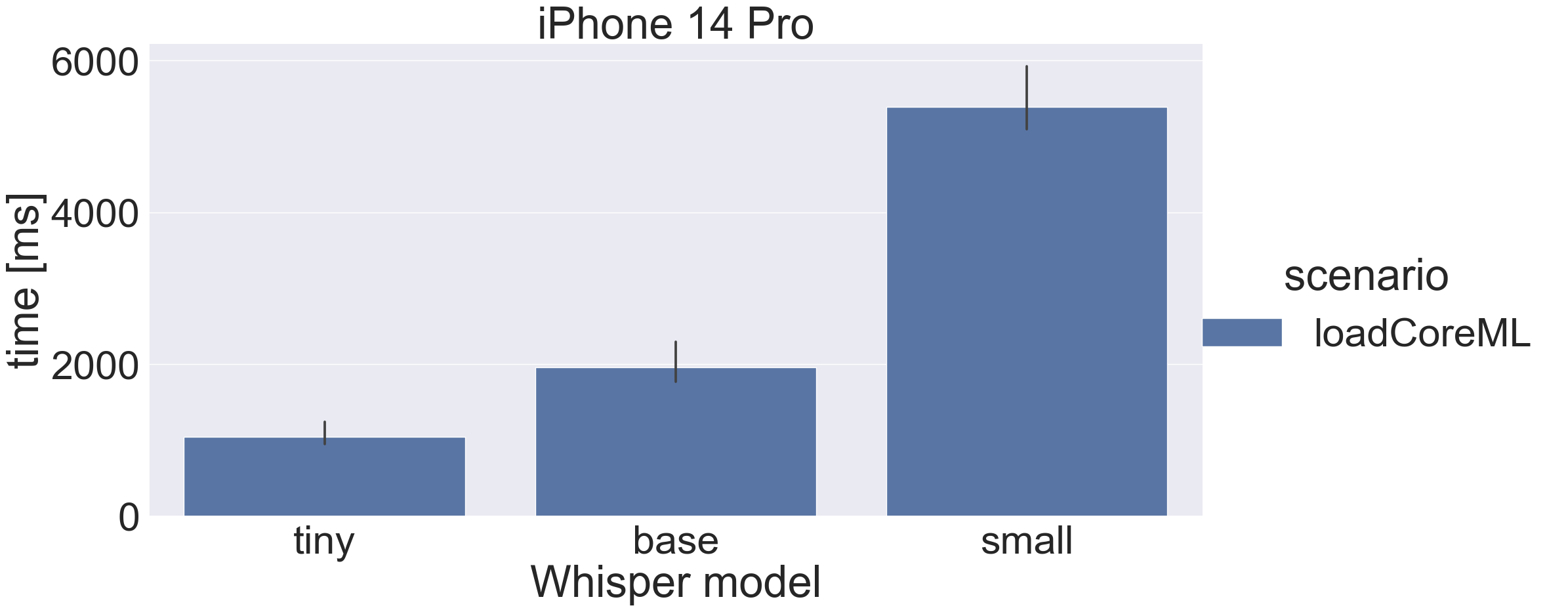
Even for the “small” model, the once-off caching time is less than 6 seconds on an iPhone14 Pro. Once I have upgraded to iOS 17 I will know if there’s a change, but I don’t have another phone to install the Beta on.
For recent phones the recommendation is to use CoreML on macOS 13.
CPU vs CoreML on macOS 13
Here are the results for transcribing 30 seconds of audio without CoreML:
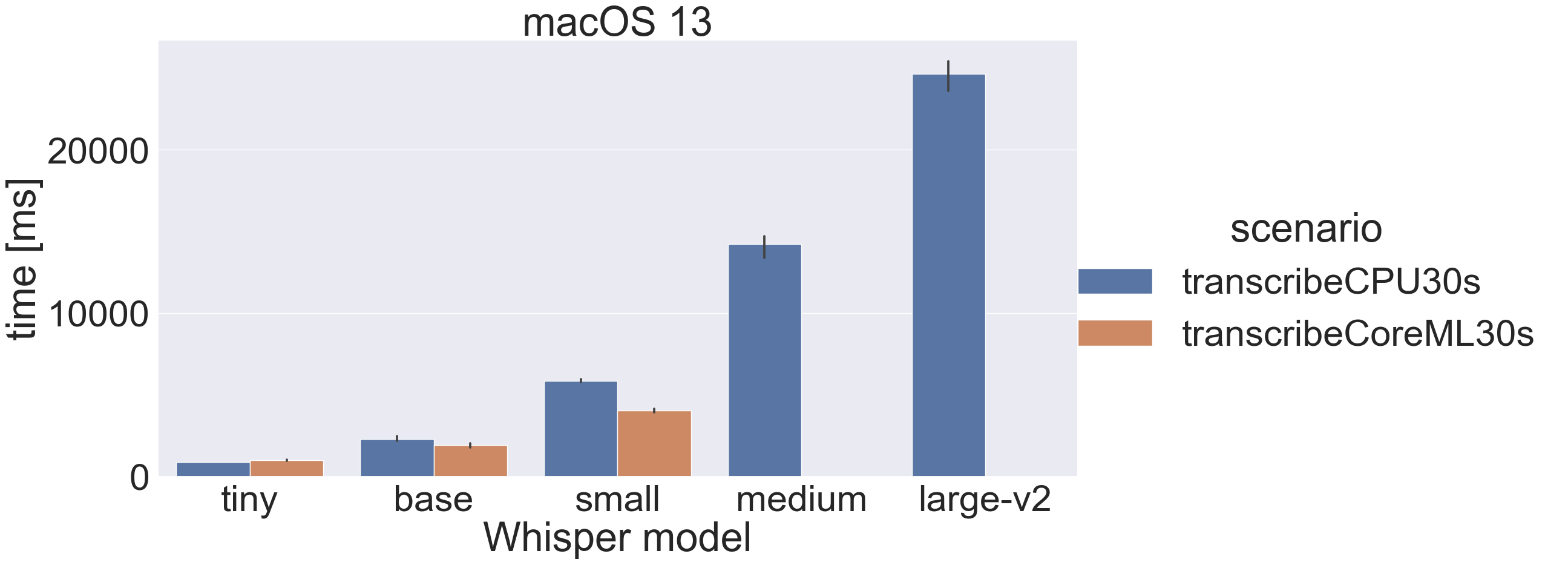
On a Mac the CoreML improvement is significant but not as impressive as on an iPhone14 Pro. The M1 Max has a previous generation of ANE (I think it’s from the iPhone 13), which explains the discrepancy.
BUT there is a problem with “small” on macOS 13… it can take 17 minutes to cache:
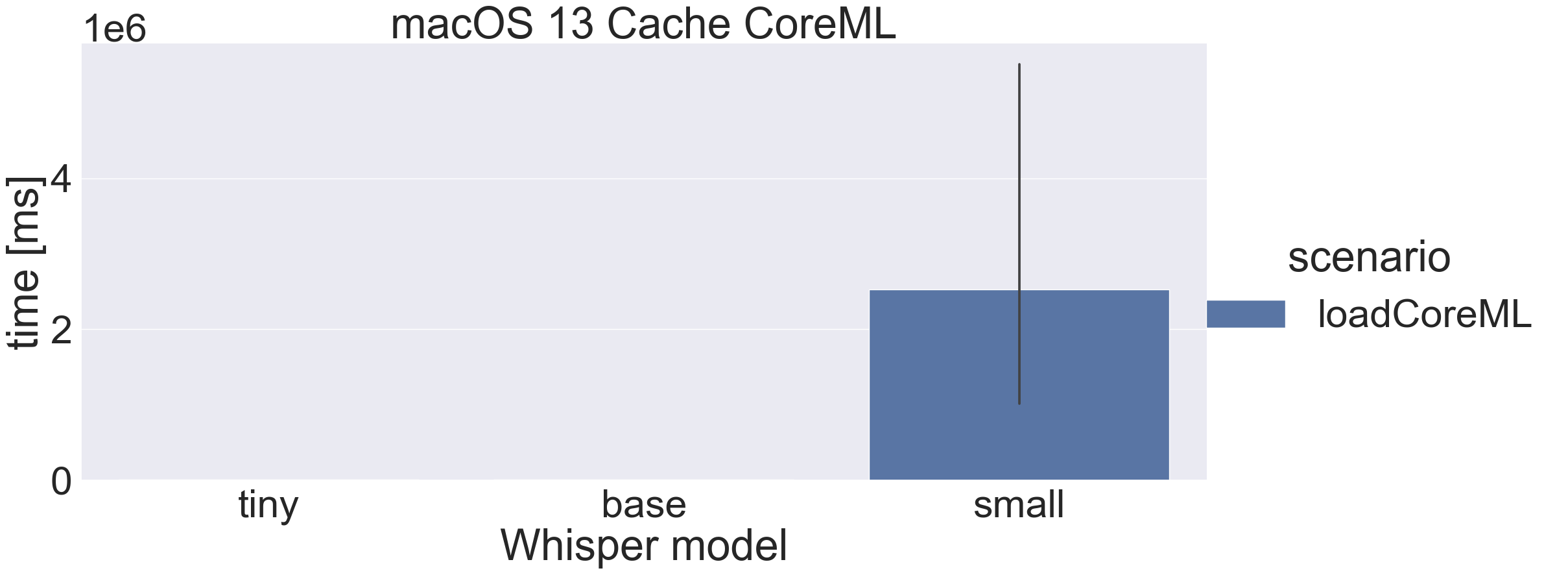
The good news is that there’s a fix in macOS 14 Beta, so “small” now caches in 34 seconds instead of 17 minutes:
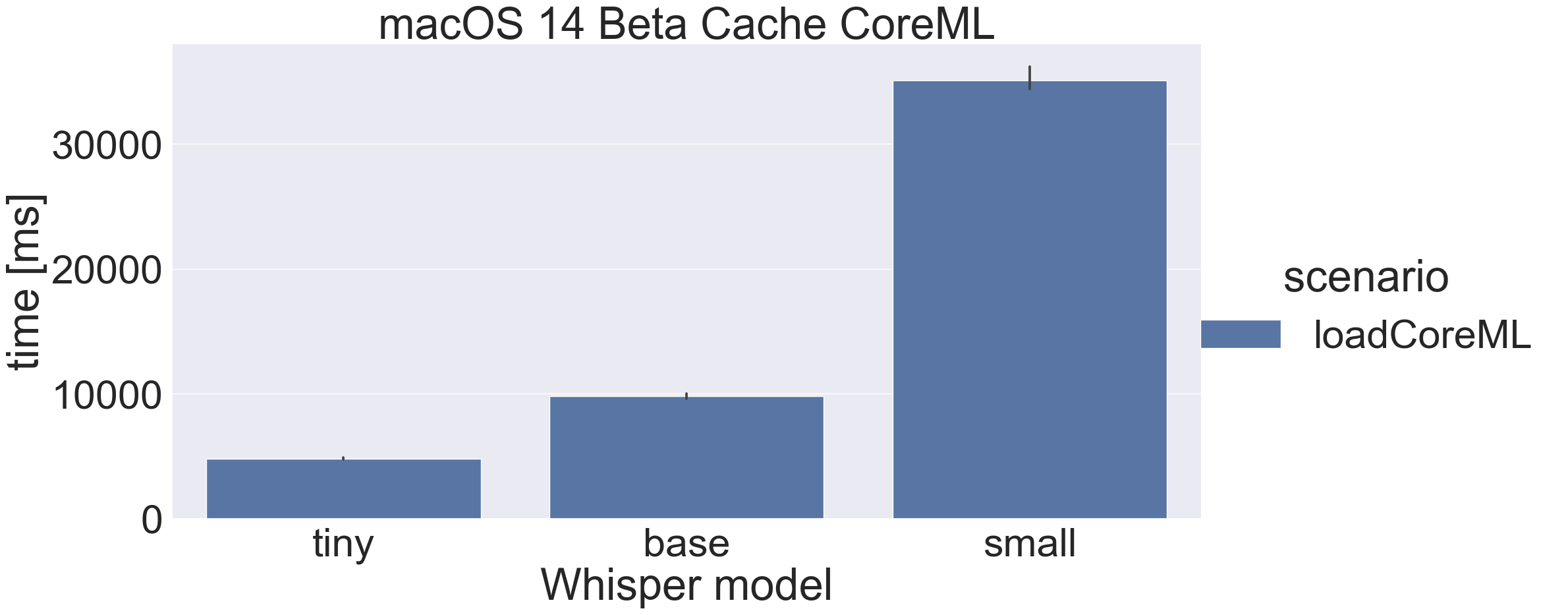
Inference time macOS 13 vs 14 Beta
I mentioned the current macOS 14 Beta is significantly slower:
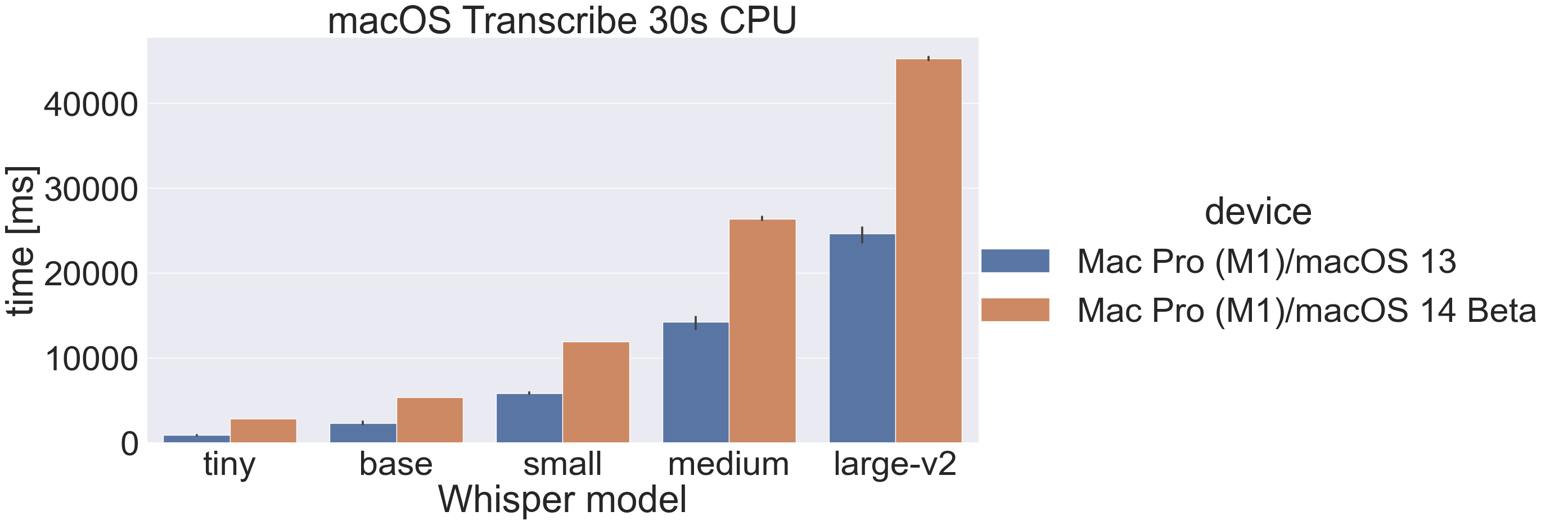
The same slowdown also occurs for CoreML. I don’t know the reason for the slowdown, I hope that it improves when macOS is released. If not, I will have to investigate.
Conclusion
As you can see there are some tricky considerations to using the Whisper models on different platforms and devices. My aim is to choose sensible defaults but let the user choose the configurations they want (with good info to support those decisions).
The next version of Hello Transcribe will offer significantly more in terms of configuring models, e.g. setting CoreML per model & beam search size. This will be supported in the UI to do a fast switch between configurations (e.g. two-tap or click change to a faster or more accurate model for the current task).