
Hello Transcribe 2.2 — now with CoreML 🚀
Introduction
tl;dr Hello Transcribe version 2.2.x now uses CoreML and that makes it 3x-7x faster. It’s available on the App Store
Georgi Gerganov (and others) have added CoreML to Whisper.cpp and it’s a game-changer for speed.
If you want to try it out in Whisper.cpp there’s a “coreml” branch, and Pull Request with instructions. It hasn’t been merged into main at this point, but it’s stable as far as I can tell.
I won’t go into too many technical details as I don’t have the depth of understanding, but essentially the encoder part of the transformer runs in CoreML, and the decoder and other supporting functions (e.g. the mel spectrogram) runs on the CPU.
The result in the app is 3x - 7x speed-up for Hello Transcribe.
One thing I noticed during development is that the automatic language detection will result in the encoder being run twice, so if you specify the language in options when using a multilingual model you will see a performance improvement.
I also realised that setting the language to “auto” when using the English model will have an unnecessary performance penalty for the same reason. For 2.2 the language is set to “English” when using an English model.
There are two caveats:
- Users need to download the new models which include the compiled CoreML model.
- The first time the CoreML model is loaded it is optimized for the device. This may take a long time (up to a minute on my older iPhone 12 Pro), but then it is quick in future.
Benchmarks
Below are some informal benchmarks, running on my iPhone 14 Pro. For English it’s > 7x (in part because I removed the redundant call to the encoder as mentioned above). For German it’s about 4x.
“small” is now faster than “tiny” was previously, which is a HUGE upgrade.
For 15 seconds of German audio on iPhone 14 Pro:
— Ben Nortier (@bjnortier) April 6, 2023
Tiny 2.1.0: 1349ms
Tiny 2.2.1: 361ms
Small 2.1.0: 3936ms
Small 2.2.1: 1197ms pic.twitter.com/scZSQUr7i5
The multilingual performance is the most exciting part of this upgrade. Running at least “small” is required for decent multilingual transcription and previously it would be quite slow. Now decent multilingual dictation is real-time.
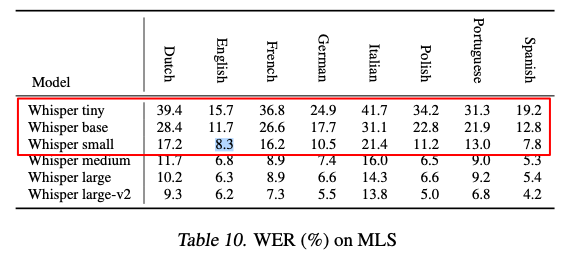
Supposedly “small” Spanish is better than English according to the published WER numbers, and German “small” performs as well as English “tiny” at the same speed:
Here’s a side-by-side screen recording of Hello Transcribe 2.1 vs 2.2:
I’m busy submitting Hello Transcribe version 2.2 to the App Store. Here’s a sneak peek at the CoreML performance improvement for “tiny” and “small” (English). It’s insane 🤯🚀#OpenAI #AI #Whisper pic.twitter.com/rkmZNTOoUd
— Ben Nortier (@bjnortier) April 11, 2023
M1 Max vs A16 Bionic
Here’s an interesting tidbit: Whisper.cpp+CoreML is faster on my iPhone 14 Pro (A16 Bionic), than on my Macbook Pro (M1 Max), likely due to the fact the the M1 is based on the A14 which was found in the iPhone 12 Pro:
What surprised me is that Whisper.cpp+CoreML is faster on my iPhone 14 Pro A16 Bionic than my MacBook Pro M1 Max, 713 vs 773ms for one sample 🤯 I suspect it's because the M1 has the same Apple Neural Engine as the A14 Bionic. #OpenAI #Whisper #AIhttps://t.co/RJ1FakBykl pic.twitter.com/7IyzjJp2NF
— Ben Nortier (@bjnortier) April 6, 2023
Whisper.cpp vs iOS Dictation
What about the built-in iOS dictation? Here’s a video of the built-in iOS dictation in Notes vs Hello Transcribe. I’m playing the audio through the speakers of my laptop so it’s not a very scientific test. Notes really struggles in this scenario:
Conclusion
This is a major leap forward for Hello Transcribe to produce accurate, fast transcriptions thanks to the amazing work by Georgi Gerganov and others.
Try it out and let me know what you think. I’m especially interested in the performance of multilingual transcriptions.
As always, if you email me I’ll add you to the TestFlight Beta group and you don’t have to pay for Pro, no questions asked.
Get it on the App Store now.